
但假如你对这些数字并不了解,或者不知道市场上的走向。
这篇文可能帮得上你。
如果你非常熟悉使用网上各种查价工具
或者你已经学过统计学,明白这些数字背后的意义是甚幺
也欢迎你逗留一下,帮我看看有没有错误。
目前网上已经有一定量的紫卡查价工具,
只要输入你的紫卡武器、属性、数值,你可以得出一个大约的价格。
但在这篇文并不是介绍各种查价工具或另一串紫卡问价片,
不,绝对不是。
这篇文是尝试解释官方给出的交易数据,来猜测紫卡市场上的情况。
但是现时官方给出的数据并没有办法完全推算出真实的状况。
只能大概去知道发生甚幺事。
下面我会提及一些统计学或数学的用词,你或者听过,或者没有。
但是这没关係,因为我解释一下。
先给一下资料来源,上面是交易资料。
在里面你会见到像这样的几行
"itemType" : "Kitgun Riven Mod",
这是指甚幺类型的武器,步枪、霰弹、手枪、近战、kitgun、zaw
"compatibility" : null,
这是指这紫卡是那个武器的,例如︰捕月,Null是指未开启。
"rerolled" : false,
这是指紫卡有没有被重骰,如果有就True,没有就Flase
"avg" : 30.08,
这是同一个武器的各张紫卡,交易金额的平均数。
"stddev" : 32.85,
这是同一个武器的各张紫卡,交易金额的标準差。
"min" : 3,
这是同一个武器的各张紫卡,交易金额的最低一个数值(最便宜)
"max" : 1000,
这是同一个武器的各张紫卡,交易金额的最高一个数值(最昂贵)
"pop" : 2.5712,
这是这武器的紫卡交易热门度,未知计算方式
"median" : 30
这是同一个武器的各张紫卡,最中间的那一个交易金额。
这是同一个武器的各张紫卡,最中间的那一个交易金额。
计算的方式各有不同,而呈现出的效果也有所不同,因此给予的数据分析方法越多,能知道更详细。
由Min 及 Max,我们只能知道所有紫卡的售价都在这个範围裏面︰
Min 3<---------->1000 Max
但是我们并不能知道他们的分布是怎样的,即是说,他们可以在以下的方式排列︰
Min 3 < o-o-oo-o-oo-o-o > 1000 Max 或者
Min 3 < ooo-oo----o-ooo > 1000 Max
我们很明显看出,这两个是不同的,但是它们仍然是在3-1000这个範围裏。
然后,我们用一个更有效的方法,用计算平均数的方法,来尝试得出一个指标︰
(金额1+金额2+金额3)/ (总共紫卡交易数)
这样的话,我们应该可以找得到一个大约中间的指标,最首最尾加起来除,应会得出两者中间的答案,所以,应该是可以有些指标性的。
由刚刚的例子可以看到一些︰
Min 3, Max 1000, avg, 30
3 <---------------------------------> 1000
儘管最小的交易金额是3,最高是1000,平均数却是30,而不是500。
这样我们可以得到几个可能︰
低于,或者等于30白金的紫卡交易数是主流
高于30的是少数,或者非常少数。
再加一个指标︰中位数
中位数是一个所有数字由大小排序后,取最中间的一个。
假如这类紫卡以9个不同价格售出︰3,10,12, 18, 30, 30, 32, 35, 1000
最中间的就是第5个,即是 [30]。
平均数、中位数都是大约[30白金]时,我们都可以说,30真的是中间的数字
但是如果这样呢...下面两个的平址数跟中位都是一样的时候,我们有甚幺办法?
< oooo-----o-----oooo >
< oo---oo--o--oo---oo >
这时候就要加入「标準差」这个方法
「标準差」有一个挺有趣的特性,我们本来假设一个正常的数据,是会这样的︰
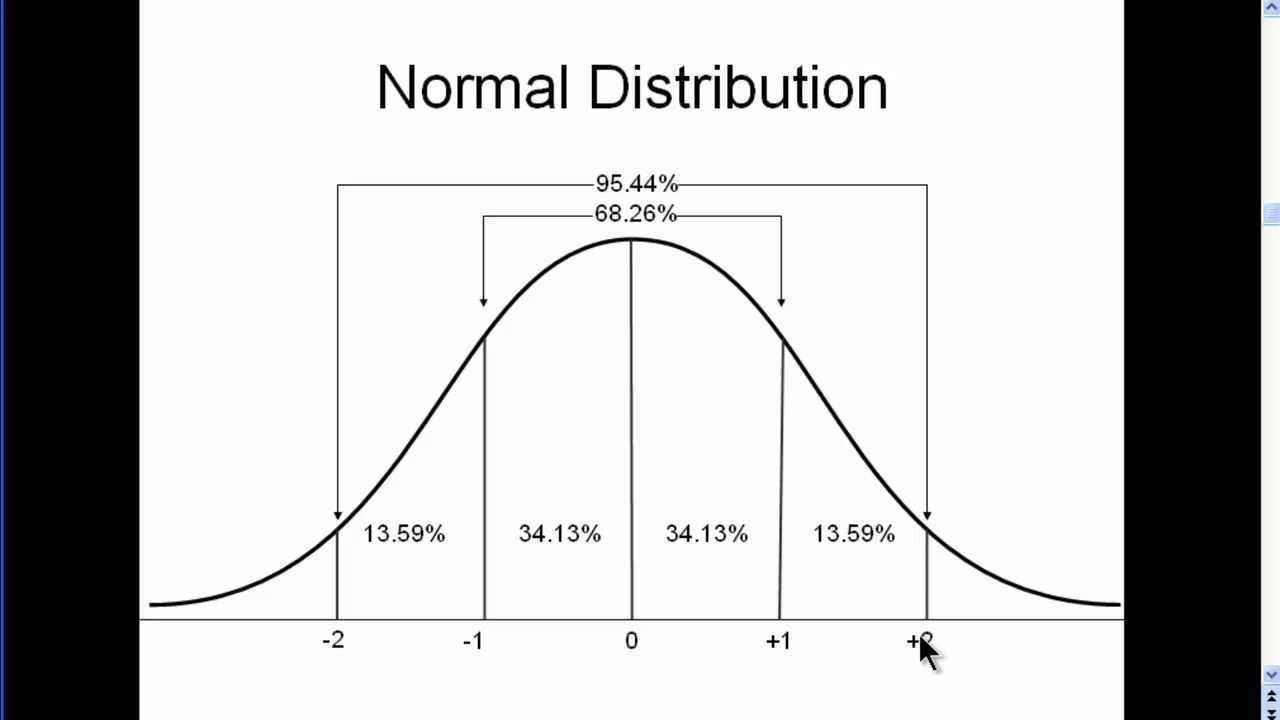
这个叫Normal distribution curve,一般来说︰
最高及最低是少数
靠中间的会很多
然后看看刚刚的数据,kitgun的std是︰32.85
如何去读呢…
1. 找出平均数,然后标示为0,30->0
2. 把这个数字加或减 (std*1),然后标为1/-1,-2.85(0) ->(-1),62.85(1)
3. 把这个数字加或减 (std*2),然后标为2/-2,-35.7(0) ->(-2),95.7(2)
4. 把这个数字加或减 (std*3),然后标为3/-3,-68.55(0) ->(-2),128.55(2)
计算完标準差后,我们得出一个很有趣的结论︰
由-1至1,是覆盖了68.26%的数据,即是说 68.26%的kitgun紫卡交易金额,是由0至62.85白金
由-2至2,是覆盖了95.44%的数据,即是说 95.44%的kitgun紫卡交易金额,是由0至95.7 白金不等
剩下的交易,只佔了所有交易的4.5%左右。
虽然这些数字是可以有这种解释,但是像刚刚例子的数字
除了知道大部分紫卡是徘徊在0-95外,其实很难知道其他的资讯。
不过每月去看这些资料时,就会出现另一个有趣的资讯,就是趋势了。
但是正态(常态)分布并不是这幺容易出现的,它很完美,是理想中的形状。
但是现实都是不完美的,所以分布跟形状都有不同。
偏度跟峰度(或过剩峰度)就能用来描述这个形状,给予一个大概的数据。

偏度是指数据较为偏向、集中在整个数据列的哪一个部分。
偏度等于0时,就是正态分布
少于0时,数据集中在较大的数字的方向,右边较高,尾巴指向负数。
大于0时,数据集中在较小的数字的方向,左边较高,尾巴指向正数。
偏度计算方式︰有很多种,我只懂得一种 (Pearson skewness coefficient #2)
(3) 乘(平均数-中位数) 除以 (stddev)
以未开kitgun为例︰
=3乘(平均数-中位数)除以stddev
=3 * (30.08-30) / (32.85)
= 0.0073 (小数后四位)
因为在-0.5至0.5之间,所以形状也是较为对称的。
但也因为是正向,有些数据是较大的(1000白金那类)。
另一种计算方式是峰度,峰度被误会为计算曲线的高峰有多高
但是主要是解释数据较为向中间集中,还是会分布在两端较远的地方。
峰度计算你需要两个数据︰标準差、样本数量
标準差就是stddev,官方有提供真好
样本数量就要由热门度推算,热门度是那紫卡的交易人数除以所有紫卡总交易人数,即係类似百分比的东西,不过没乘以100而已。
要找到样本数量,第一个要找到的是「只有一宗交易的紫卡类别」,也即是stddev等于0,并记下他的pop数值,用其他紫卡的pop值除以这个pop,得出的数字应该趋近整数。
[目标紫卡pop值] 除以 [单宗紫卡交易pop值] = 交易宗数(样本数量)
有了标準差及样本数量,那我们就可以开始列出峰度的公式了。
峰度 = 第四中心距 / 方差
到现在为止都看不懂是正常的,但是慢慢看下去
方差= 标準差^2 (标準差二次方)
方差= (官方给的stddev)^2
这是方差的构成式︰方差 = (每一个点与平均数的距离)的二次方 (除以) (样本数量)
没错,我们是没有每一个点,所以我们用一般方法计算 (每一个点与平均数的距离)的二次方 这东西
但是我们有方差,也有样本数量,所以只要稍微调一下位置就可以了。
(每一个点与平均数的距离)的二次方 的总和 = 方差 (乘以) (样本数量)
因为方差 = 标準差的二次方,所以把这个放回去,你就得到这个公式︰
(每一个点与平均数的距离)的二次方 的总和 = 标準差二次方 (乘以) (样本数量)
峰度的公式就是围绕在 样本数量、(每一个点与平均数的距离)的总和,这两个元素来建成的。
峰度 = (样本数量) (乘以) (每一个点与平均数的距离的总和)的四次方 (除以) (样本数量) (除以) (方差的二次方)
过剩峰度的公式则是︰ (峰度的公式结果) 再 (减三)
若过剩峰度为0,代表分布有如正态分布。
若过剩峰度大于0,代表往中间集中,离群数据较少。
若过剩峰度少于0,代表越往外面扩散,离群数据较多。
以未开kitgun为例︰
pop: 2.5712
stddev: 32.85
单宗紫卡交易pop为︰0.0017
1. 先求未开kitgun交易数量…
2.5712 (除以) 0.0017 = 1512.4705 (取1513)
2. 求(每一个点与平均数的距离)的二次方 的总和…
方差 乘以 交易数量
= 32.85^2 x 1513
=1079.1225 (取1079) x1513
=1632527
3. 把它开根号
根号(1632527) = 1277.7038
4.找出(每一个点与平均数的距离)的总和 的四次方
1277.7038^4 = 嗯...
5.列出过剩峰度公式
过剩峰度 = (样本数量) (乘以) ((每一个点与平均数的距离)的总和 的四次方) (除以) ((每一个点与平均数的距离)的总和) 的二次方 的二次方 (减3)
=1513 x 根号(1632527)^4 (除以) 根号(1632527)^2^2 (减3)
=1513 x (1) -3
=1510 (WT.........)
我开始怀疑我有没有算错了甚幺
分子跟分母两个都一样,这样除会是1吧,但是计算上我做错了甚幺呢。

![《星际战甲(Warframe)》【问题】请问为什么我warframe创建帐号的时候打完电子邮件和密码完会一直卡在[我要用的平台]](https://www.qpb2b.com/zhuanqu/warframe/100014.jpg)




![《星际战甲(Warframe)》【心得】 创伤 Prime~[[取得]]~[[介绍]]~[[心得]]唷~](https://www.qpb2b.com/zhuanqu/warframe/10005.jpg)









